zotero--优化记录
zotero--优化记录
gyhhl本文分享了一些利用zotero提高文献管理的免费插件和方法,主要涉及到主页期刊和影响因子的展示,文献笔记模板,文献矩阵,全文双语对照翻译,标题和摘要翻译,ai辅助阅读文献与obsidian的联用等
有些图片可能会加载缓慢
1 前提准备
1.1 所需插件
- Better Notes for Zotero
- Ethereal Style
- Jasminum
- Translate for zotero
- Actions and Tags for Zotero
- obsidion Note for Zotero
- pdf2zh
- awesome gpt
- zotero paper agent
1.2 插件下载
所需插件在以下网站免费下载
zotero插件商店
2 影响因子以及分区展示
此项需要在安装EtherealStyle插件 的基础上才能实现
顺带说一下Translateforzotero插件 。可以实现划词划句翻译
这个插件再下载好后再设置界面配置相关的翻译服务即可。其中腾讯翻译每月有500万token的免费额度。

https://www.easyscholar.cc/ 点击这个网站进行注册
具体设置请看官网说明文章【点击】
3 自定义标注颜色和文本
此项功能用到的是EtherealStyle插件
在高亮显示以后,会自动在左侧添加上相应的标签
通过这个自定义的标签,可以通过另外一个插件对多篇文献实现文献矩阵。方便快速对比。具体方法请看后面。当然这个插件本身也支持文献矩阵,不过需要收费。
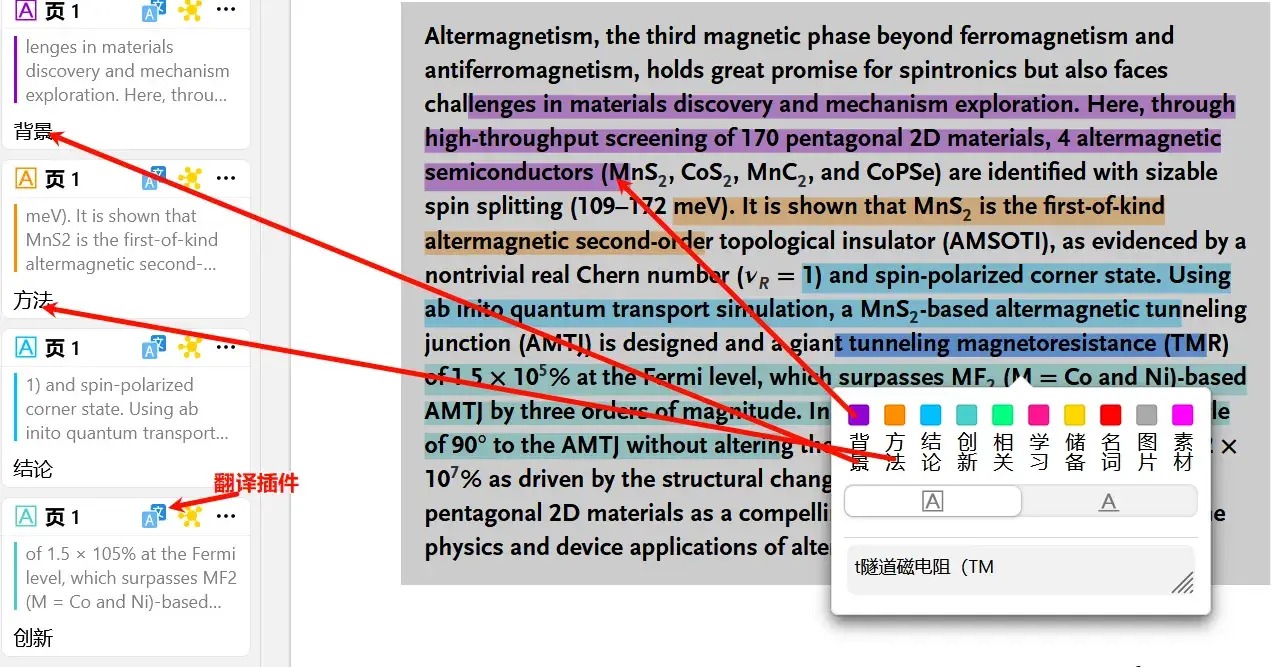
安装Ethereal Style插件以后,可通过shift+p,选择标注打开,也可通过zotero界面中的编辑—>设置—>阅读界面(标注颜色编辑) 如图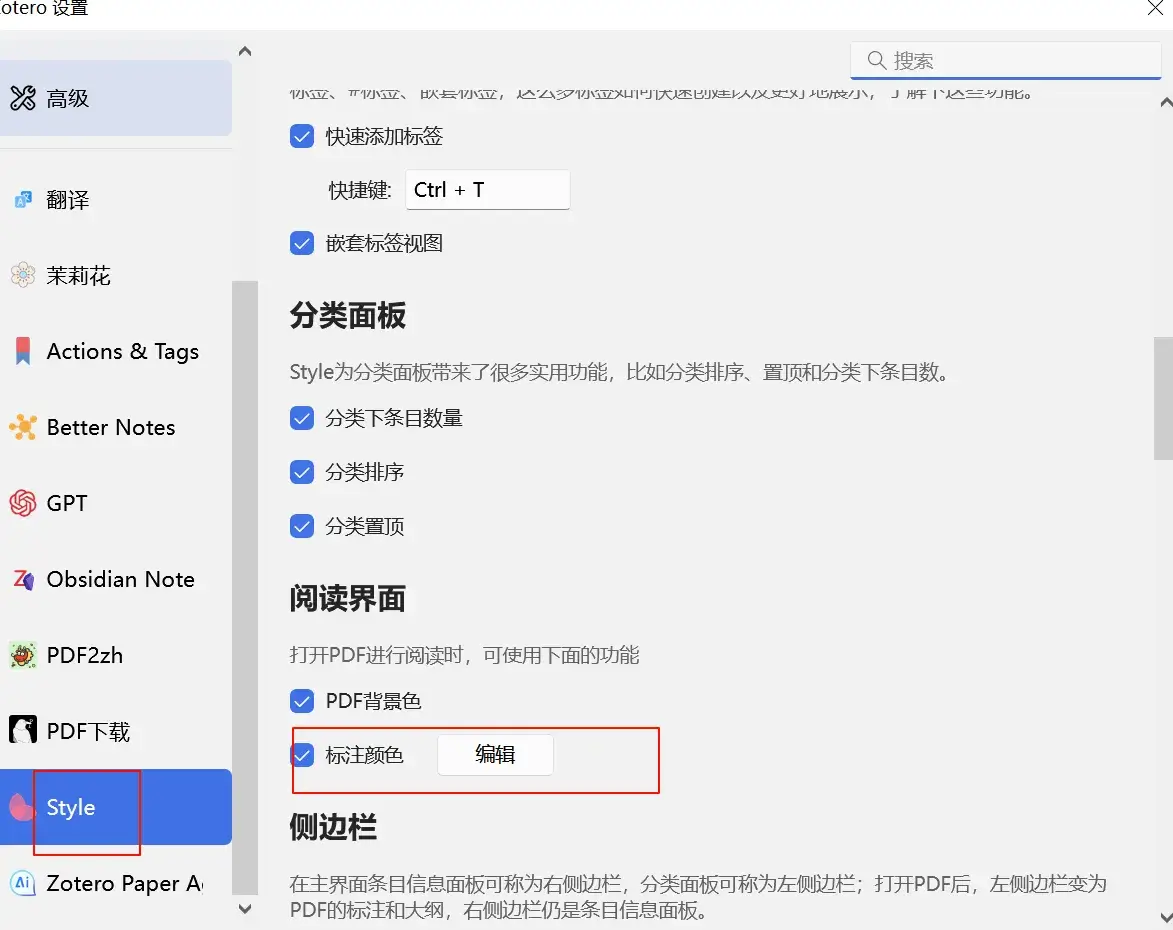
然后在下面的界面设置即可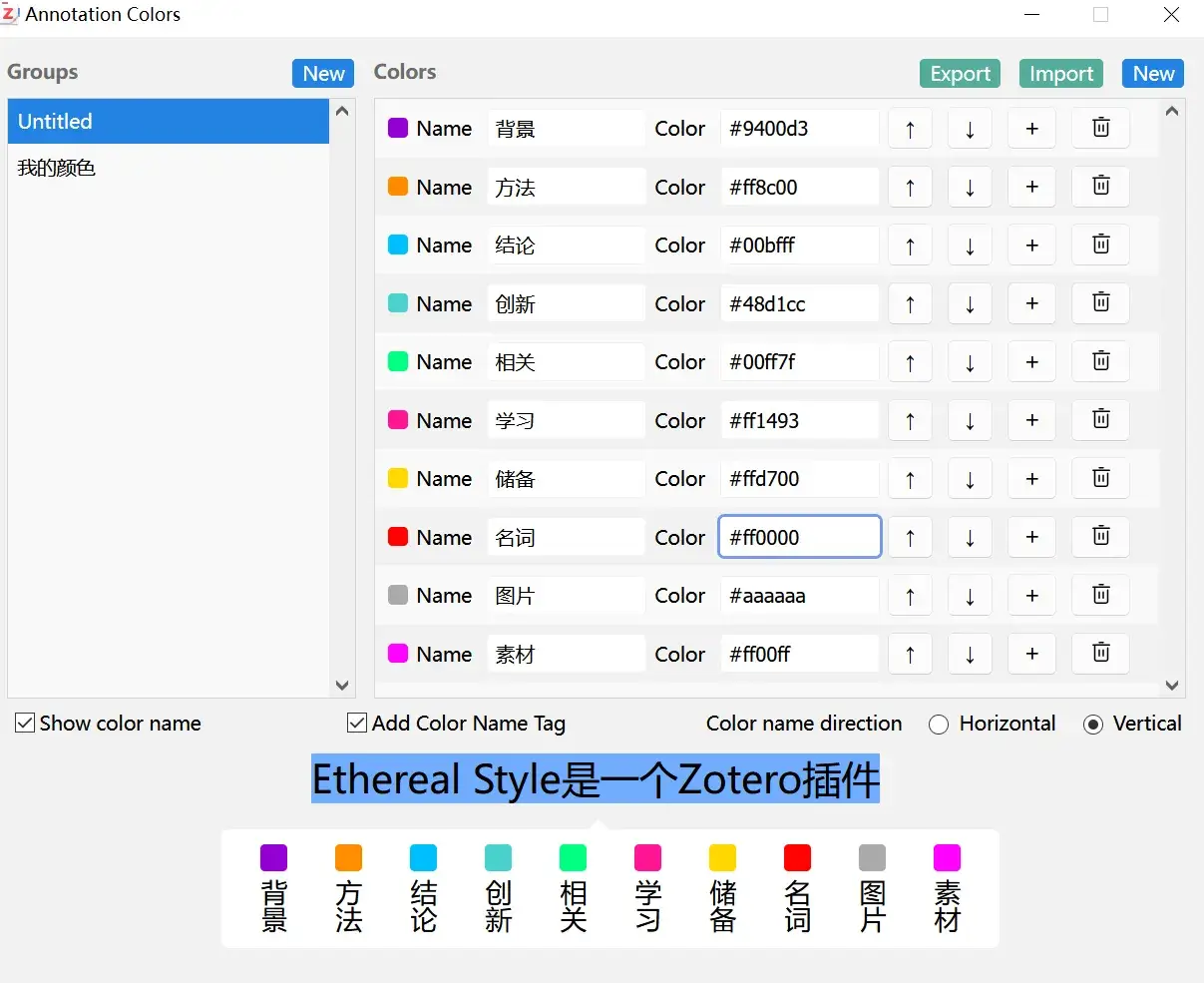
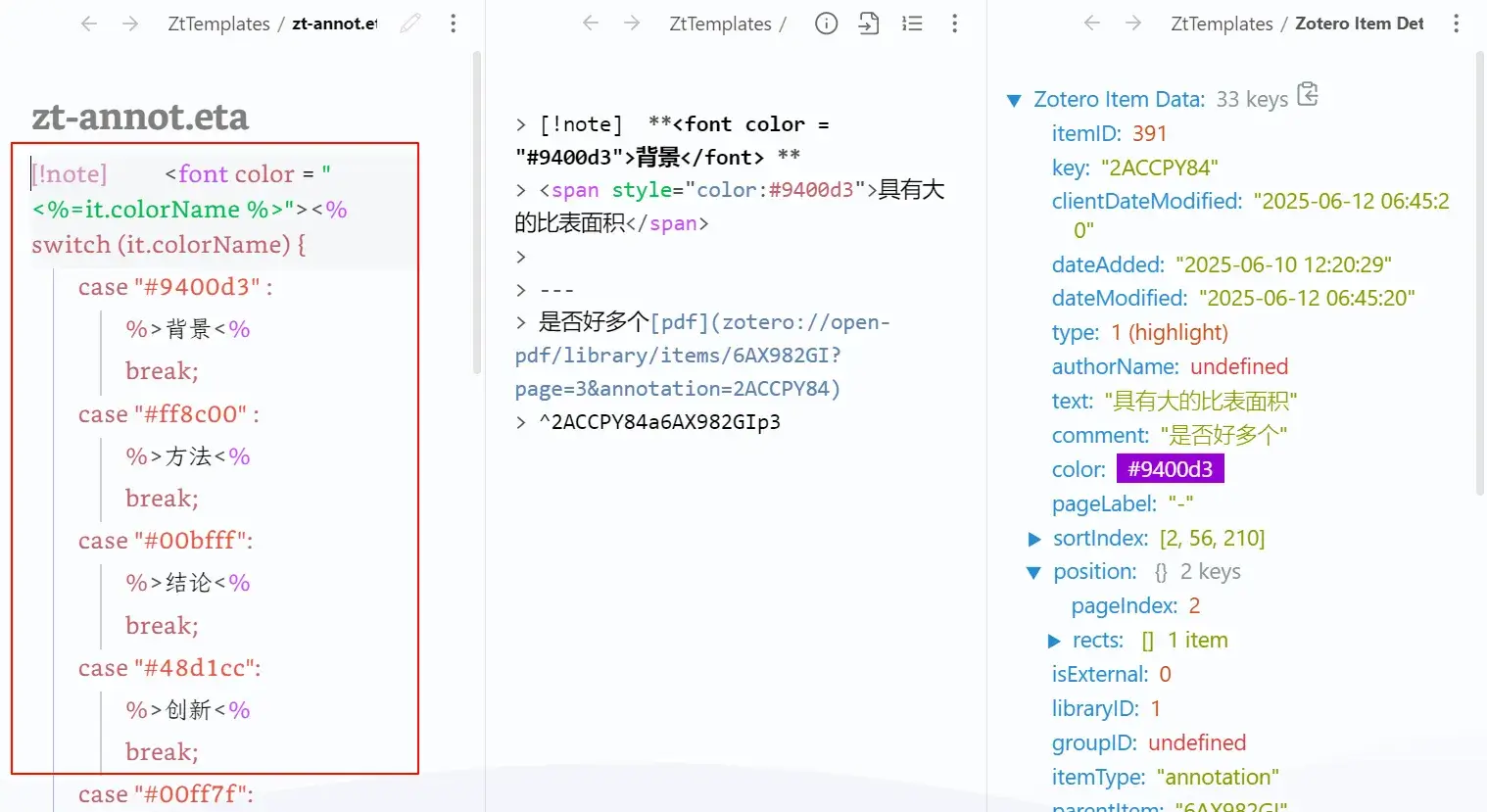
4 笔记模板的配置
这个功能主要用到了BetterNotesforZotero插件
在通过笔记模板生成英文文献笔记之前,记得需要先右键翻译标题和摘要(Translate for zotero插件)。
配置不成功以及需要更多笔记模板代码的可通过点击此链接获取
下图为通过模板生成的笔记,具体内容可通过修改模板代码来适配
将以下代码(中英文文献通用)复制粘贴即可。可通过修改来达到自己想要的效果
1 | <html> |
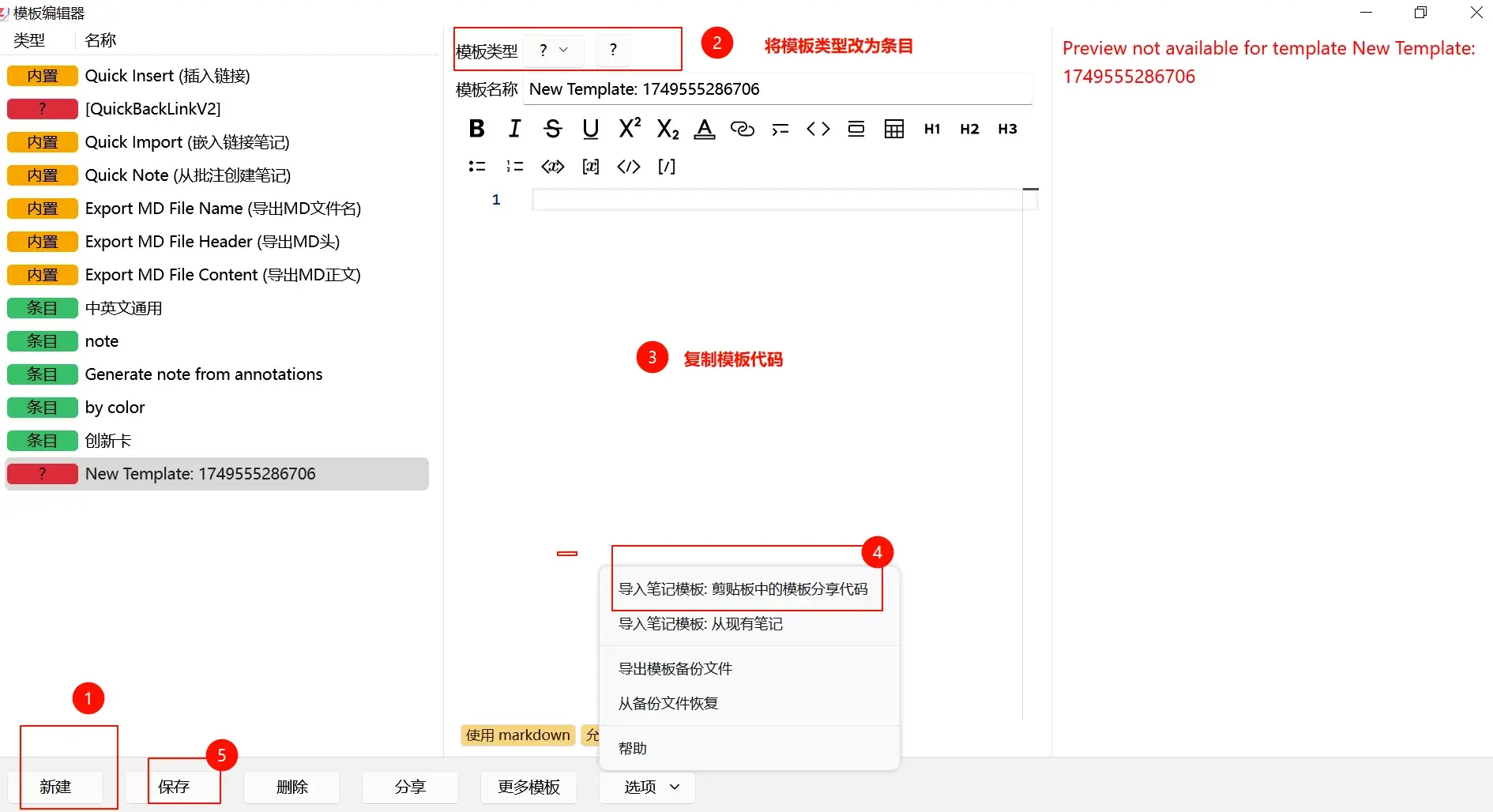
- 首先在zotero界面中,点击工具—>模板编辑器。打开以下面板。
- 然后新建——将模板类型改为条目—-复制模板代码——-选项—> 导入笔记模板——保存

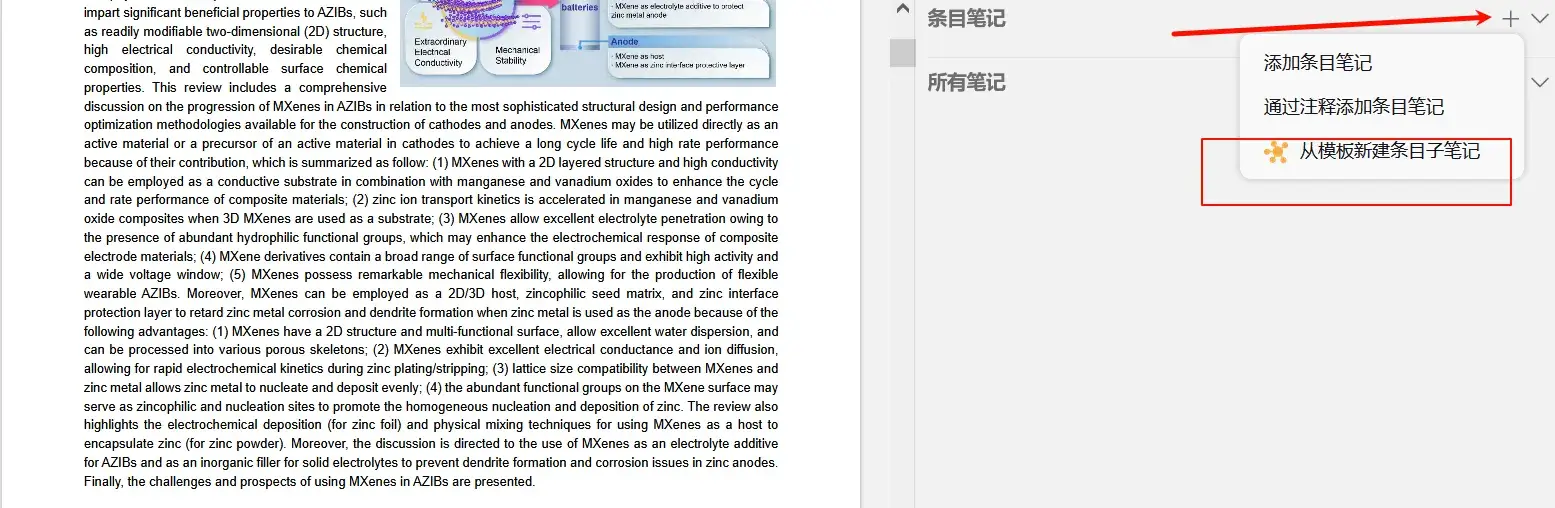
- 之后打开想要添加笔记的附件pdf,在最右边选择笔记—>条目笔记—->从模板新建条目笔记—>选择刚刚创建的模板即可
5 文献矩阵
- 利用 Ethereal Style插件实现,不过需要收费
- 利用awesome gpt 插件实现,在后面ai辅助阅读中会提到
- 利用 Actions and Tags for Zotero插件 免费实现
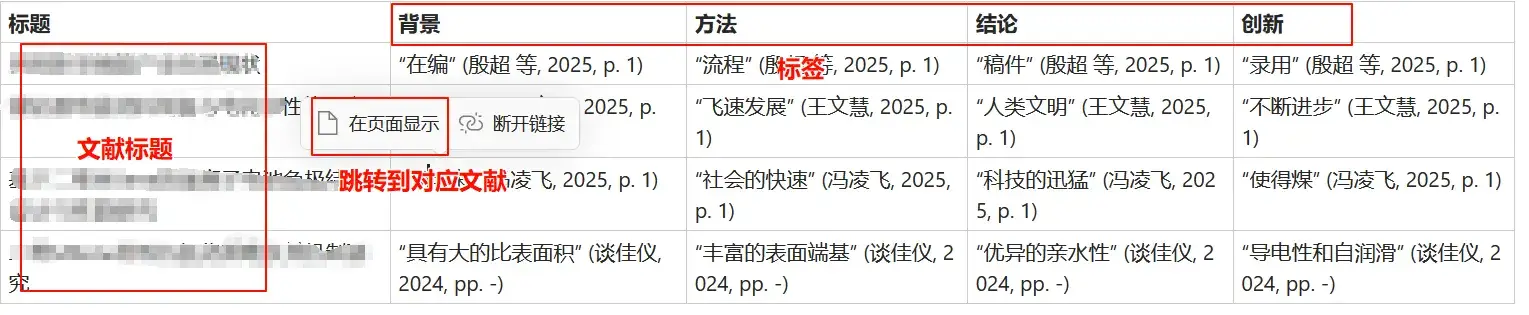
此次只介绍第三种,它是通过总结阅读文献时高亮标注的标签来实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
/**
* @author Mulei
* 脚本功能:从所有选中的条目中提取指定 PDF 附件内带有指定“注释标签”(Zotero 注释自身的 tag)的注释(转换为 HTML),
* 并将同一文献中同一注释标签的内容合并到同一单元格,最后生成一个表格。
*
* 使用说明:
* 1. 在 Zotero 中,使用自带的 PDF 阅读器打开 PDF,并对需要的文字做高亮或注释,然后在注释的右侧面板中添加标签(tag),如“背景”、“材料”。
* 2. 选中一个或多个条目后运行此脚本(使用传入的 items 或 item 变量)。
* 3. 脚本会弹窗依次提示输入新笔记的标题和要提取的注释标签(多个标签请用英文/中文逗号、英文/中文分号分隔,如“背景;材料”或“背景,材料”等)。
* 4. 脚本会先自动删除每个条目中已生成的、包含这些标签关键字的提取注释笔记(避免重复)。
* 5. 然后遍历每个条目,找出其 PDF 附件中带有相应标签的注释,将注释文本(高亮或注释内容)放到对应列中。
* 6. 最后将所有提取到的注释内容以表格形式合并生成一个新的独立笔记,并弹窗显示处理结果。
*/
if (item) return; // 仅对所有选中项执行一次
const Zotero = require("Zotero");
const window = require("window");
const console = require("console");
// 使用传入的 items 或 item 变量
let selectedItems = [];
if (typeof items !== "undefined" && items.length > 0) {
selectedItems = items;
} else if (typeof item !== "undefined") {
selectedItems = [item];
} else {
window.alert("请先选择要处理的文献");
return;
}
// 弹窗提示输入新笔记的标题
let noteTitle = window.prompt("请输入新笔记的标题:");
if (!noteTitle) {
noteTitle = "合并注释";
}
// 弹窗提示输入需要提取的注释标签
let annotationTag = window.prompt(
"请输入需要提取的注释标签(逗号、分号分隔),例如:\n(默认包含标题)\n\n创新,背景,材料,方法,结论,摘录,笔记\n\n"
);
if (!annotationTag) {
window.alert("未输入注释标签,操作终止");
return;
}
/**
* 将输入拆分成数组,支持:
* - 英文逗号 (,)
* - 中文逗号 (,)
* - 英文分号 (;)
* - 中文分号 (;)
*/
let annotationTags = annotationTag.split(/[,,;;]/)
.map(tag => tag.trim())
.filter(tag => tag.length > 0);
window.alert(`开始处理 ${selectedItems.length} 个条目,请稍候...\n你输入的标签: [${annotationTags.join(", ")}]`);
/**
* 删除每个条目中已生成的、包含任一指定注释标签关键字的提取注释笔记
* 删除条件:笔记内容以 <div data-citation-items 开头且包含 annotationTags 中任意一个关键字
* (此处只是简单地用 includes 判断 HTML 内容)
*/
async function deleteIndividualAnnotationNotes(items, annotationTags) {
for (let item of items) {
const noteIDs = item.getNotes();
for (let id of noteIDs) {
let note = Zotero.Items.get(id);
let noteHTML = note.getNote();
if (noteHTML && noteHTML.startsWith('<div data-citation-items')) {
// 如果笔记中包含任意一个用户输入的标签关键字,就将其删除
if (annotationTags.some(tag => noteHTML.includes(tag))) {
Zotero.Items.trashTx(id);
}
}
}
}
}
/**
* 从单个条目中,提取其 PDF 附件中所有带有 annotationTags 中任意一个标签的注释,
* 并将同一标签的注释文本合并到同一个字符串。
* @param {Zotero.Item} item - 当前处理的条目
* @returns {Object} 注释对象,键为注释标签,值为合并后的注释内容
*/
async function extractAnnotationsFromItem(item) {
// 预先给每个用户指定的标签初始化为空字符串
let annotationsObj = {};
annotationTags.forEach(tag => {
annotationsObj[tag] = "";
});
const attachments = item.getAttachments();
for (let attachmentId of attachments) {
const attachment = await Zotero.Items.getAsync(attachmentId);
// 仅处理 PDF 附件
if (attachment.attachmentContentType === "application/pdf") {
const annots = attachment.getAnnotations();
if (annots && annots.length > 0) {
for (let annot of annots) {
// 检查此注释的标签
if (annot.getTags && Array.isArray(annot.getTags())) {
let tagsOnAnnot = annot.getTags().map(tagObj => tagObj.tag);
console.log("此注释的标签:", tagsOnAnnot, ";用户指定的标签:", annotationTags);
// 如果此注释至少包含 annotationTags 中的一个标签,就把文本归到相应标签下
for (let wantedTag of annotationTags) {
if (tagsOnAnnot.includes(wantedTag)) {
try {
// 获取此注释的完整HTML(高亮或批注)
let annotJSON = await Zotero.Annotations.toJSON(annot);
let res = Zotero.EditorInstanceUtilities.serializeAnnotations([
{ ...annotJSON, attachmentItemID: annot.parentID }
]);
let cleanHTML = res.html;
// 去掉外层 <div>(如果有)
if (cleanHTML.startsWith('<div') && cleanHTML.endsWith('</div>')) {
cleanHTML = cleanHTML.replace(/^<div[^>]*>/, '').replace(/<\/div>$/, '');
}
// 累加到对应标签下(此处没有添加分隔符,如果需要换行可自行加上 "<br>")
annotationsObj[wantedTag] += cleanHTML;
} catch (error) {
console.error("转换注释为 HTML 时出错:", error);
}
}
}
}
}
}
}
}
return annotationsObj;
}
/**
* 遍历所有选中的条目,提取 PDF 附件中带有指定标签的注释,
* 并以表格形式生成一个新的独立笔记。
* 表格第一列为标题,后续列为用户输入的标签;同一标签的注释内容合并在同一单元格。
*/
async function combineAnnotationsIntoSingleNote(items) {
let tableData = [];
for (let item of items) {
let title = item.getField("title") || "无标题";
try {
let itemAnnotations = await extractAnnotationsFromItem(item);
tableData.push({ title, annotations: itemAnnotations });
} catch (error) {
console.error(`处理文献 "${item.getField("title")}" 时出错:`, error);
}
}
if (tableData.length === 0) {
window.alert("未找到任何符合条件的注释");
return;
}
// 构建 HTML 表格,列顺序按照 annotationTags 顺序
let combinedHTML = `<h1>${noteTitle}</h1>\n`;
combinedHTML += `<table border="1" cellspacing="0" cellpadding="5">\n`;
// 表头:第一列为标题,后续列为用户指定的各个标签
combinedHTML += `<tr><th>标题</th>`;
annotationTags.forEach(tag => {
combinedHTML += `<th>${tag}</th>`;
});
combinedHTML += `</tr>\n`;
// 每个文献对应一行
tableData.forEach(row => {
combinedHTML += `<tr>`;
combinedHTML += `<td>${row.title}</td>`;
annotationTags.forEach(tag => {
let cellContent = row.annotations[tag] || "";
combinedHTML += `<td>${cellContent}</td>`;
});
combinedHTML += `</tr>\n`;
});
combinedHTML += `</table>\n`;
// 创建新的独立笔记(standalone note),使用第一个条目的库 ID
let noteItem = new Zotero.Item("note");
noteItem.libraryID = items[0].libraryID;
noteItem.parentID = null; // 独立笔记
await noteItem.saveTx();
// 设置笔记内容为生成的表格 HTML
noteItem.setNote(combinedHTML);
await noteItem.saveTx();
return noteItem;
}
// 先删除旧的提取笔记,再合并生成新的独立笔记
deleteIndividualAnnotationNotes(selectedItems, annotationTags).then(() => {
combineAnnotationsIntoSingleNote(selectedItems).then((noteItem) => {
if (noteItem) {
let successMsg = "成功创建合并笔记: " + noteItem.getNoteTitle();
console.log(successMsg);
window.alert(successMsg);
} else {
window.alert("处理过程中未能创建合并笔记。");
}
});
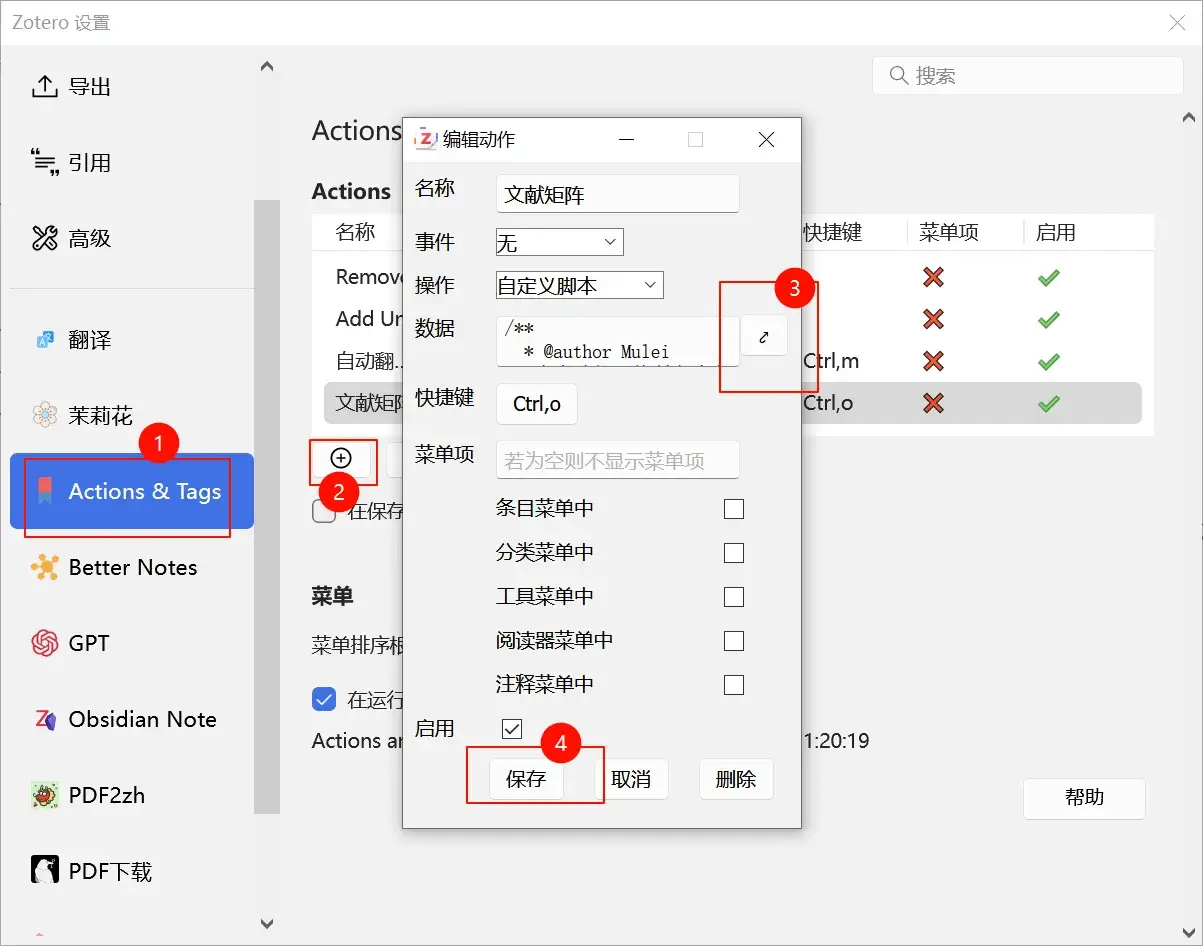
});- 安装完Actions and Tags for Zotero插件后,点击编辑—>设置—->选Actions and Tags for Zoter—>新建事件—->粘贴代码—->保存即可
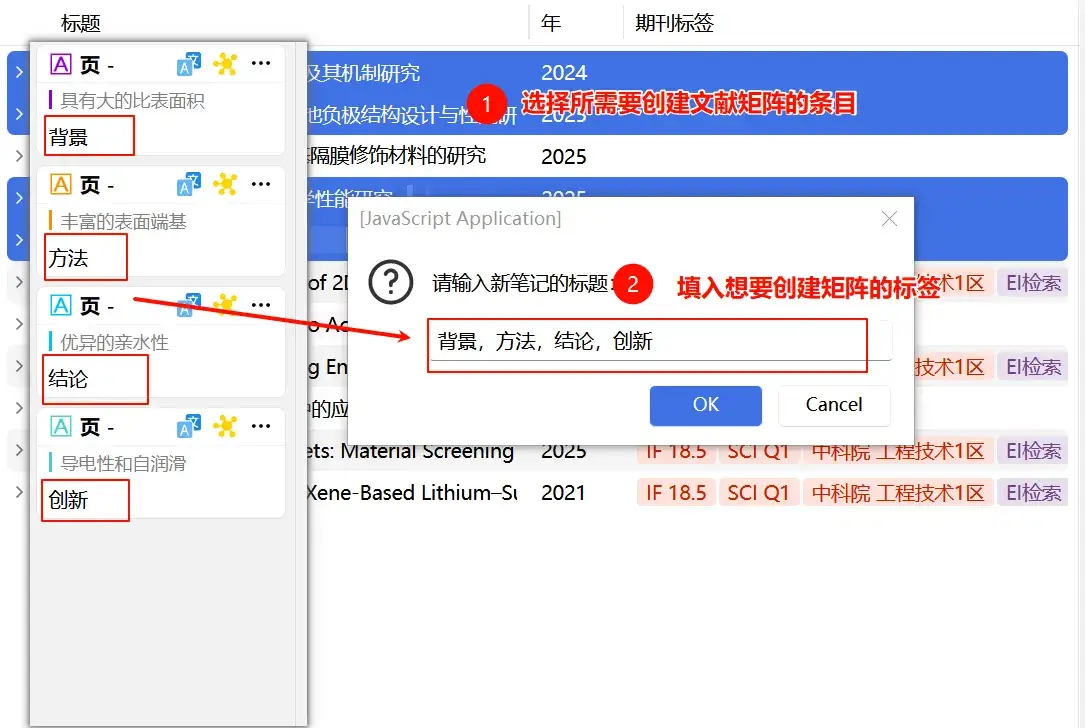
- 选择需要创建文献矩阵的条目,通过设置的快捷键启动事件,然后输入笔记标题,输入标签即可
- 安装完Actions and Tags for Zotero插件后,点击编辑—>设置—->选Actions and Tags for Zoter—>新建事件—->粘贴代码—->保存即可

6 全文翻译
全文对照翻译有以下几种。
- 通过 Ethereal Style 插件实现
选中需要翻译的条目—->shift+p——>全文翻译即可。会改变原来的pdf版式,仅有译文 - 通过zotero沉浸式翻译插件实现
沉浸式翻译提供zotero沉浸式翻译插件不过需要收费。可以使用沉浸式翻译网页版本 每月有免费额度。基本够用。 - 使用zotero-pdf2zh插件实现。
支持大多数的大模型。能自定义翻译服务。免费。不过配置比较繁琐。时间不多的还是使用沉浸式翻译较好。



详细的配置方法请查看官方文档
zotero-pdf2zh官方地址
此插件基于pdfmath此开源项目实现。更多功能请查看此项目
服务配置
- 首先电脑需要安装python环境。
- 推荐直接下载miniconda创建虚拟环境。一步到位
第一步 创建目录 存储所需文件
- 创建并进入zotero-pdf2zh文件夹
- 下载server.py文件
1 | # 1. 创建并进入zotero-pdf2zh文件夹 |
测试PDF2zh的安装
pdf2zh 1.pdf —service bing # 1.pdf是待翻译的文件
等待翻译结束,如果失败了,说明上一步的安装出现问题。这一步会使用bing免费服务翻译文件。
1.pdf要求在当前目录下
如果以上测试后出现进度条。没有报错。且在当前目录下出现 1-dual.pdf 和 1-mono.pdf则正常
然后再当前目录下新建server.py和config.json文件
将以下代码分别复制到json文件和py文件
1 |
|
1 | import os |
然后再终端输入uv run server.py 8888即可。此处的8888要和zotero-pdf2zh插件中对应
1 | * Running on all addresses (0.0.0.0) |
运行后出现这个即可表示正常。
插件配置
点击编辑—>设置—>pdf2zh—>配置翻译服务即可
注意要在config.json中对应好api和相应的模型。用量大的话可选择一些免费的模型调用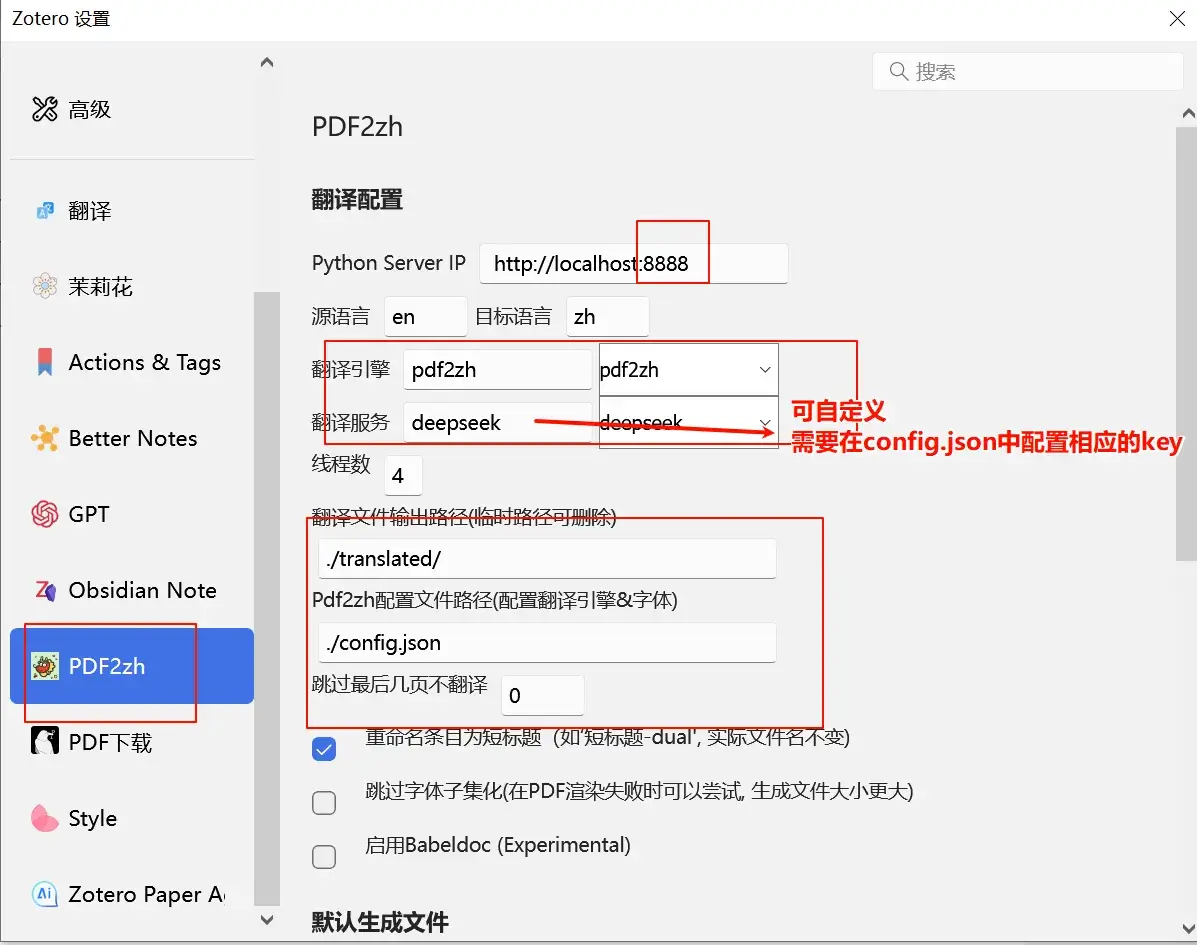
最后,选中需要翻译的文献条目,然后右键选择pdf2zh相应的翻译类型。等待即可。翻译完成后会出现在当前条目下。,每次翻译时都要确保服务正确启动
此处推荐下如果不想每次都手动开启服务的话可以使用quiker工具(能用的到的地方很多)。设置好后可以一键启动。
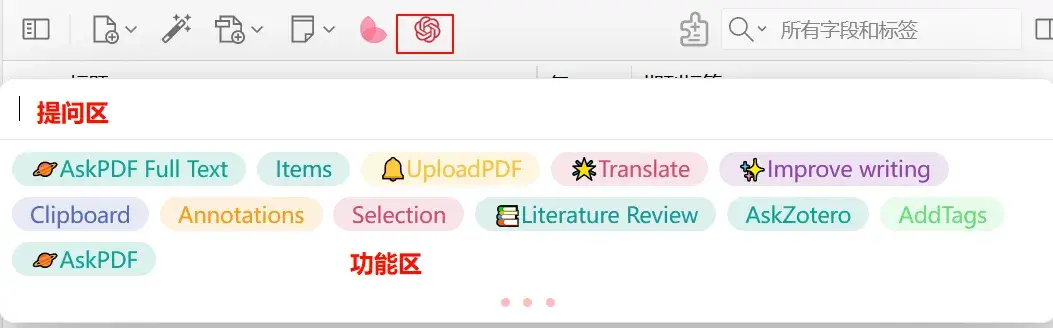
7 AI辅助阅读
此处暂时推荐两个插件 awesome gpt或者zotero paper agent
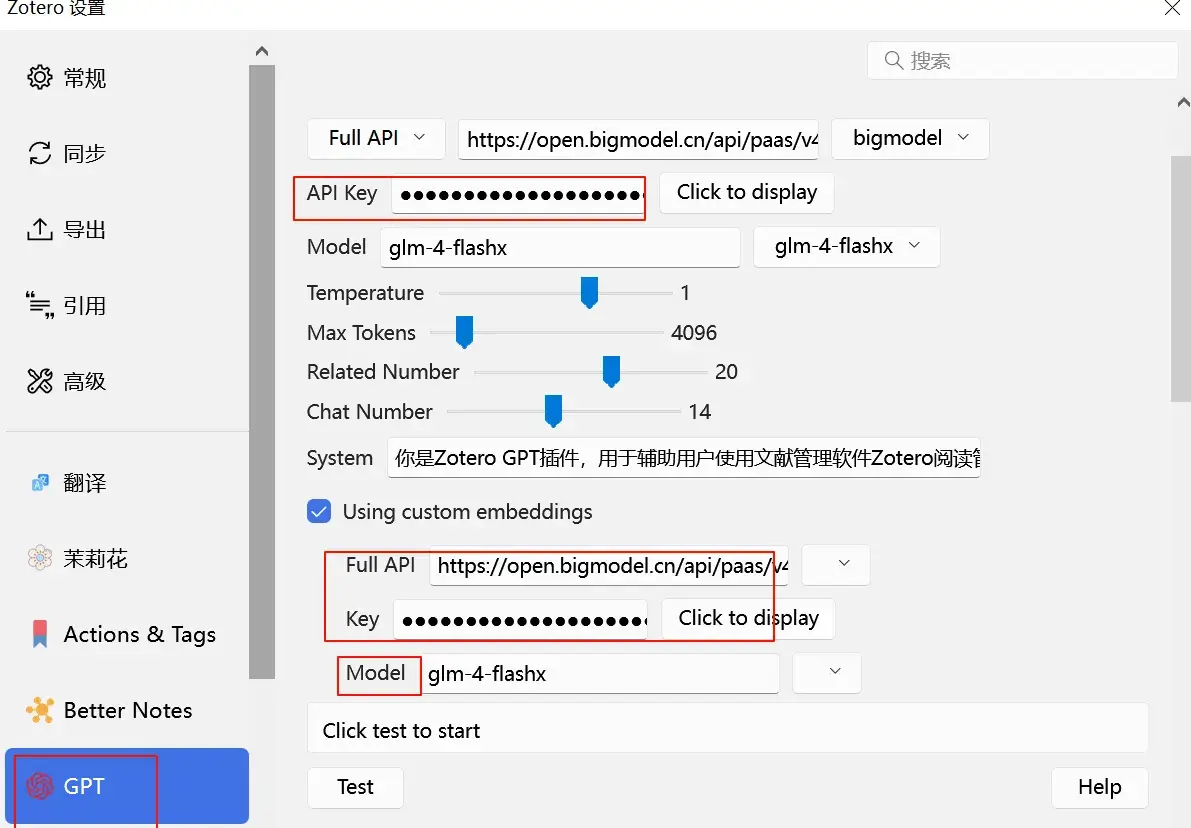
zotero paper agent 不需要额外配置。只需要在用时登陆即可。支持deepseek和kimi。轻便简洁
awesome gpt需要配置api key.内置功能较多。可自定义。支持文献综述.免费版不支持侧边栏个人感觉用起来没有zotero paper agent 方便
如果有quiker的话,也可以。有很多的动作库支持。如果您想在电脑任何一个界面使用ai,而不想另外打开浏览器或者切换其他界面的话

8 联用obsidian笔记
如果习惯用obsidian做笔记的话可以试一下
- 此处用到zotero插件为obsidion Note for Zotero 和 Better Notes for Zotero
用到obsidian的ZotLit插件
obsidion Note for Zotero和ZotLit联用,可以使得pdf中高亮显示的标签同步到obsidian中
- Better Notes for Zotero可以使得zotero中生成的笔记同步到obsidian中
这是只同步标签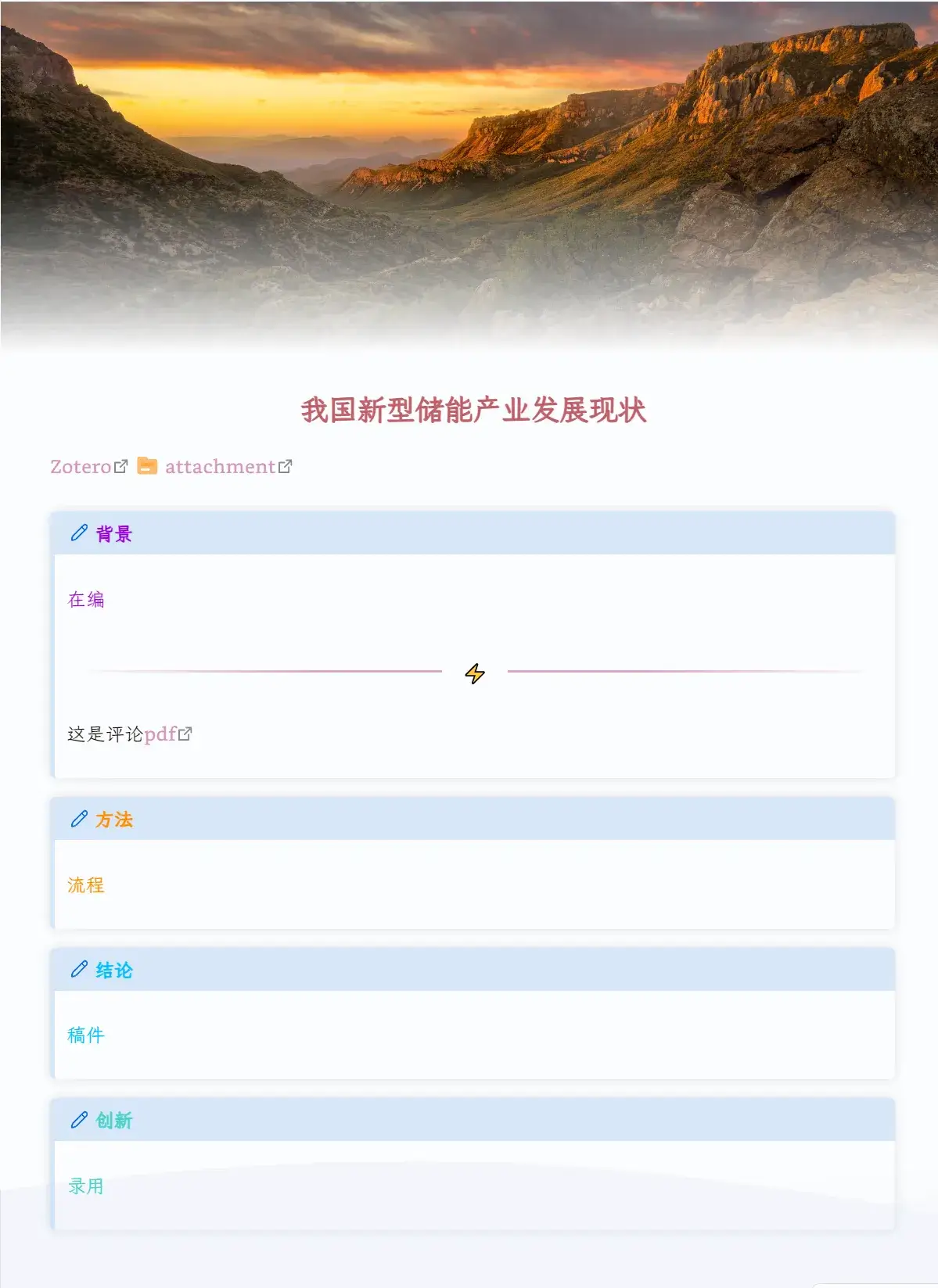
这是笔记同步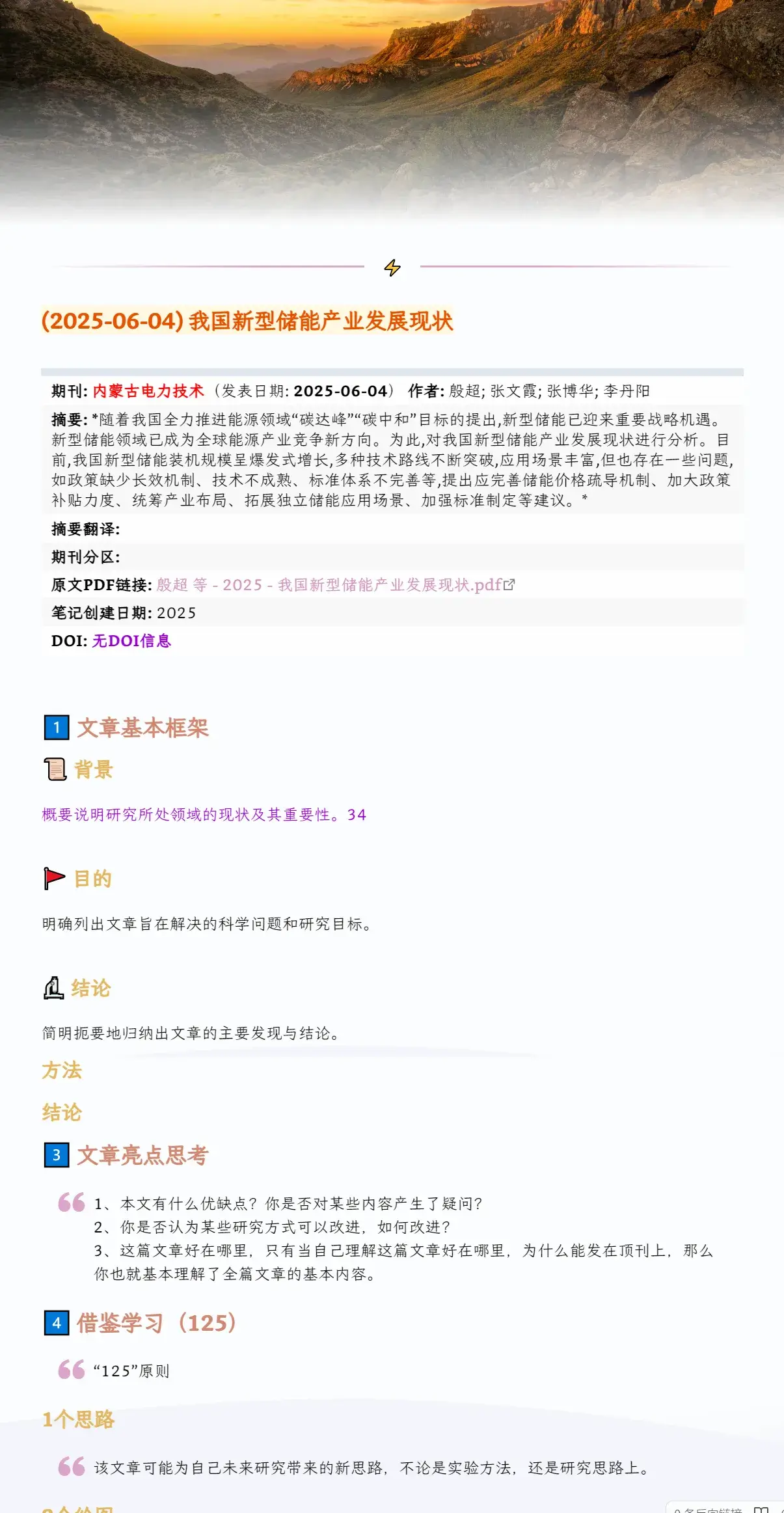
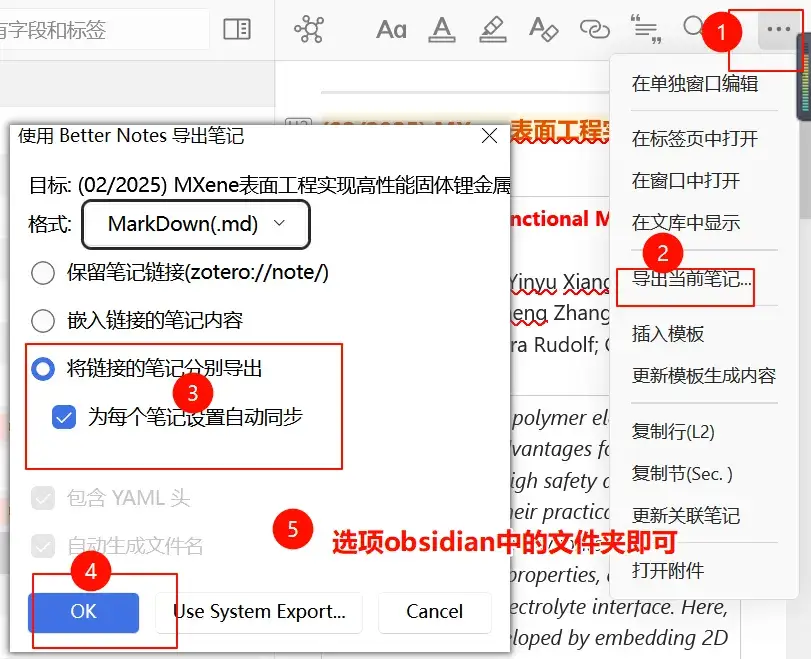
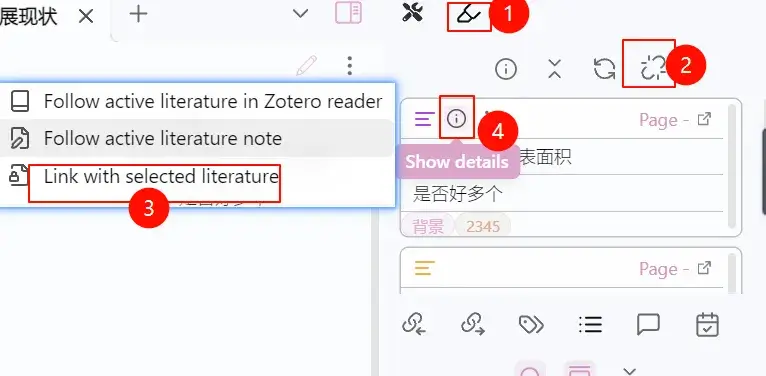
1 | [!note] **<font color = "<%=it.colorName %>"><% switch (it.colorName) { |